DCGAN
by Seunghoon Lee, Seonjong Kim
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, Soumith Chintala [ICLR 2016]
1. Introduction
컴퓨터 비전에서 레이블이 지정되지 않은 이미지와 비디오가 무제한으로 있다면 좋은 representation을 학습할 수 있으며, 이는 image classification과 같은 다양한 지도 학습 작업에 사용될 수 있다. 본 논문의 저자들은 좋은 이미지 표현을 구축하는 방법으로 GAN을 훈련하는 것을 제안한다. 저자들은 특히 GAN의 generator/discriminator를 feature extractor로 사용함으로써 좋은 성능을 보장할 수 있으며, GAN 자체도 maximum likelihood techinque의 훌륭한 대체재가 될 수 있다고 한다.
본 논문의 기여는 다음과 같다.
- Deep Convolutional GAN(DCGAN)이라는 아키텍쳐를 만들어 Convolutional GAN의 아키텍처 topology에 대한 제약을 제안하고 평가하여 대부분의 환경에서 안정적으로 훈련할 수 있도록 한다.
- 훈련된 discriminator들을 이미지 분류 작업에 사용하며 다른 unsupervised algorithm과 경쟁적인 성능을 보인다.
- GAN에서 학습한 필터를 시각화하고 특정 필터가 특정 객체를 그리는 방법을 배웠음을 보인다.
- Generator가 생성된 샘플을 조작할 수 있는 벡터 산술 특성을 가지고 있음을 보인다.
2. Related Work
- 레이블이 없는 데이터로부터의 Representation learning
- Clustering on the data(e.g. K-means)
- Leveraging the clusters for improved classification scores
- Hierarchical clustering of image patches
- Auto-Encoder
- Deep belief networks
- 이미지 생성
- Parametric (Models with fixed number of parameters) : MNIST 등과 같은 단순한 data generation에는 용이하지만 flexibility가 낮기 때문에 이미지 생성에는 성과가 아직 없다.
- Non-Parametric (Models which number of parameters grow along-side the amount of training data) : 기존 이미지의 데이터베이스에서 매칭을 수행하며 특정 분포를 따르지 않아 flexible.
- CNN 내부 시각화
- Neural Network(NN)에 자주 제기되는 문제는 이들이 ‘black-box’ 방식이며 내부에서 어떤 방식으로 작용하는지 사람이 알기 어렵다는 점이다.
- CNN에서 Zeiler et. al (Zeiler & Fergus, 2014)는 deconvolution과 maximal activation을 filtering 하는 것으로 각 convolution가 어떤 작업을 하는지 대략적으로 알게 되었고, Morvintsev et al.은 gradient descent를 input에 사용하는 것으로 어떤 이미지가 특정 filter를 activate하는지 알아보았다.
3. Model Architecture
지도학습에서 흔히 사용되고 있는 CNN을 이용하여 GAN의 성능을 향상시키는 것은 모두 실패로 돌아가왔다. 저자들은 흔히 사용되던 CNN 구조에서 벗어나 고품질/성능의 생성모델을 훈련시킬 수 있는 새로운 계보의 architecture를 찾아냈다.
Modifying three changes to CNN architecture
-
Convolution Net : Deterministic spatial pooling function을 strided convolution으로 대체하여 네트워크가 자체의 spatial downsampling을 학습할 수 있도록 한다. 해당 논리는 그대로 generator에 적용되어 generator가 자체적으로 spatial upsampling과 discriminator를 학습할 수 있게 한다.
-
Convolutional features 위의 fully connected layers를 제거 : Global average pooling을 가장 흔한 예로 들 수 있는데, 보통 이는 모델의 안정성을 증가시켰지만 수렴 속도를 저하시킨다. 저자들은 이 통찰을 이용하여 highest convolutional feature를 generator의 input과 discriminator의 output에 직접적으로 연결시킨다. 모델의 architecture는 Figure 1을 통해 볼 수 있다.
-
Batch Normalization : Batch normalization은 각 unit에 대한 input을 mean & unit variance가 0이 되도록 정규화하여 poor initialization으로 인한 문제를 해결하는 것으로 학습을 안정화시킨다. 비록 batch normalization의 유용성과 당위성에 대해서는 갑론을박이 존재하지만, 현재까지 알려진 바로는 computation을 많이 소모하더라도 효과적인 결과를 나타내기 때문에 본 논문의 저자들은 이를 활용한다. 특히 GAN에서는 모든 sample들이 하나의 point로 collapse하는 현상이 자주 일어나는데(mode collapse), batch normalization은 이를 방지하는데 주 역할을 한다고 여긴다.
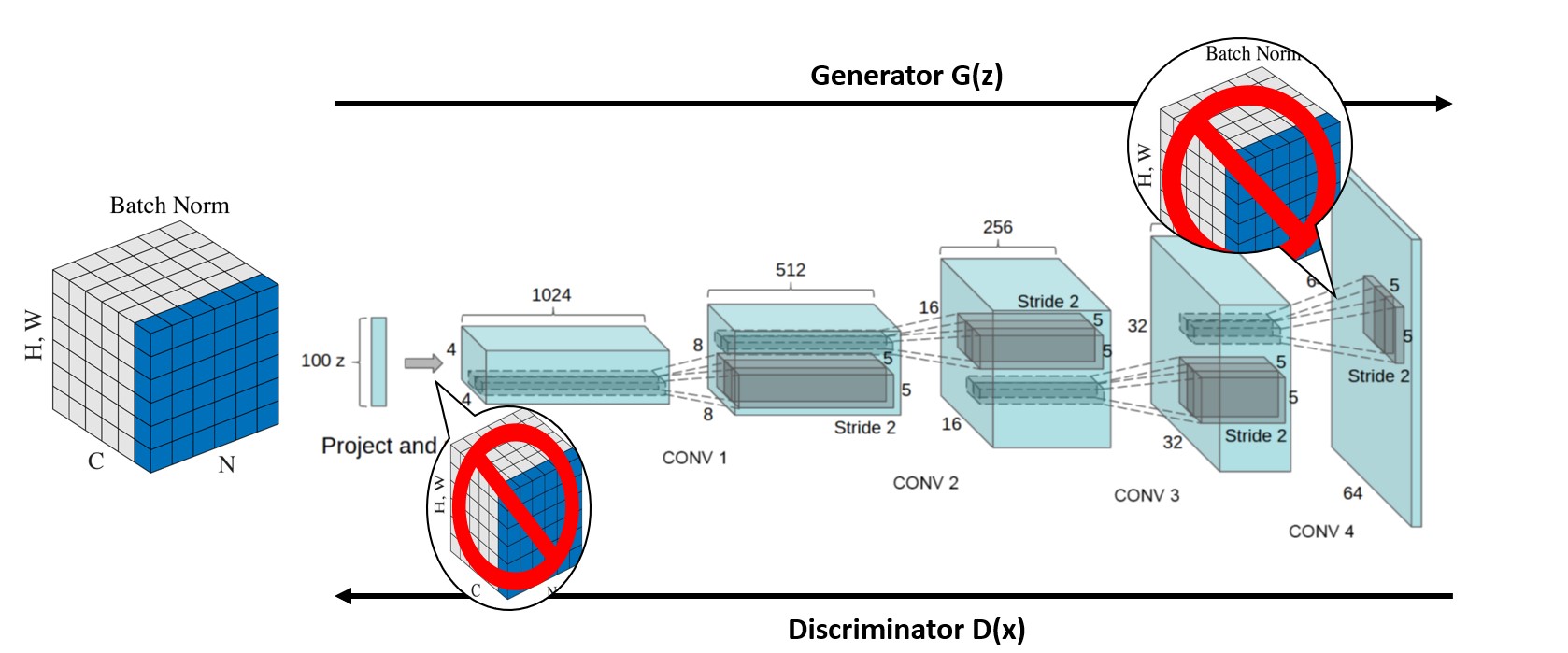
다음은 본 논문에서 제시한 DCGAN을 만들기 위한 architecture guideline이다.
Architecture guidelines for stable Deep Convolutional GANs Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator). Use batchnorm in both the generator and the discriminator. Remove fully connected hidden layers for deeper architectures. Use ReLU activation in generator for all layers except for the output, which uses Tanh. Use LeakyReLU activation in the discriminator for all layers.
Details of Adversarial training
DCGAN은 Large-scale Scene Understanding(LSUN), Imagenet-1k, Faces dataset에 훈련되었다.
LSUN은 더 많은 데이터와 더 높은 해상도의 이미지 생성에 따라 모델이 어떻게 확장되는지 확인하기 위해 훈련되었다. Figure 2는 1 epoch 후의 sample들이며, Figure 3은 convergence 이후의 sample들이다. 해당 생성 이미지를 통해 DCGAN은 overfitting이나 training example을 단순히 기억하는 것을 통해 고품질의 이미지를 생성하지 않는 다는 것을 알 수 있다. 특히, 더욱에나 generator가 기억하는 것을 억제하기 위해 3072-128-3072 de-noising dropout regularized RELU autoencoder를 32x32 downsampled center-crops of 훈련 example에 적용 시키는 방식으로 de-duplication을 진행한다.
Imagenet-1k는 32x32 min-resized center crop 된 상태로 사용 되었으며, Faces dataset은 웹상에 존재하는 1만명의 300만개의 이미지로 만들어졌다. 각 결과는 Figure 10과 11에서 볼 수 있다.




4. Validation
Unsupervised representation learning algorithm의 품질을 평가하는 일반적인 기술 중 하나는 supervised dataset에 feature extractor로 적용하고 이러한 기능 위에 fit된 선형 모델의 성능을 평가하는 것이다.
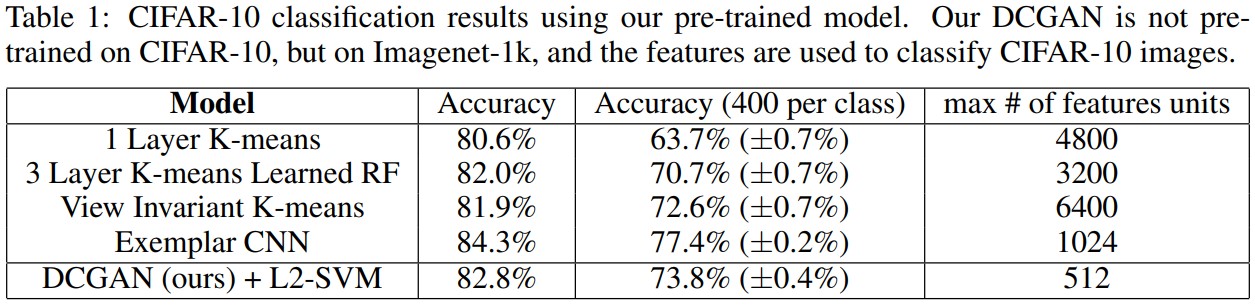
Supervised tasks를 위해 DCGAN에서 학습되는 representation의 품질을 평가하기 위해 DCGAN을 Imagenet-1k로 훈련시키고 모든 layer에서부터 오는 discriminator의 convolutional feature를 사용한다. 이 결과 82.8%의 정확도를 내며 Table1에서 보이는 K-mean 기반의 방식들보다 높은 정확도를 보이지만, Exemplar CNN보다는 낮은 정확도를 갖는다.
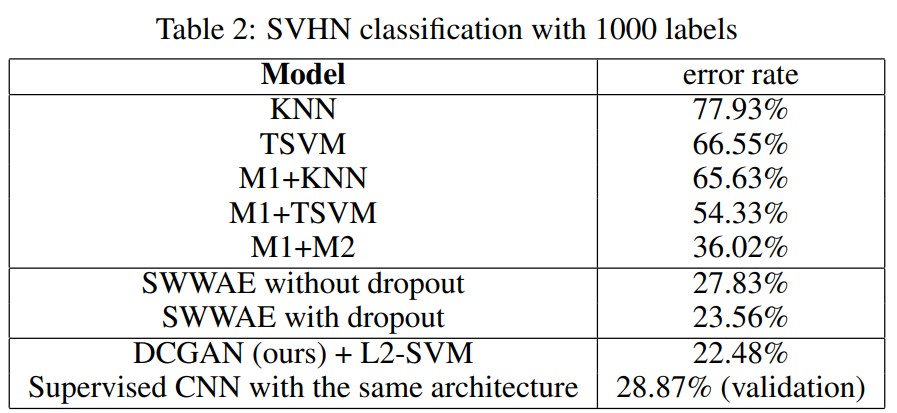
StreetView House Numbers dataset(SVHN) 또한 평가를 위해 사용되었는데, DCGAN은 다른 방식들에 비해 현저히 낮은 error rate를 보인다.
5. Visualization
Investigating
Visualization에 앞서 latent space의 landscape를 확인하며 space가 계층적으로 collapse되는 과정을 본다. 저자들은 이 실험을 위해 대상 물체에 bounding box를 직접 그린 뒤, logistic regression을 사용하여 feature activation이 해당 부분에 적용 되었는지를 보고 판단한다. Figure 4를 확인인하는 것을 통해 모델이 이미지 생성에 있어 어떤 표현을 학습했는지 볼 수 있다.

Figure 5는 DCGAN이 어떤 계층적 feature를 배웠는지 나타낸다.

Manipulating the Generator Representation
DCGAN의 generator는 특정 물체(예: 침대, 창만, 램프 등)를 훈련하여 생성한다. 본 논문의 저자들은 이러한 feature가 취하는 형태를 알아보기 위해 generator에서 창문을 완전히 제거해보는 실험을 한다. 2번째로 높은 convolution layer feature에서 해당 feature activation이 창문을 가르키고 있는지 확인을 한 뒤 해당 feature map들은 drop 된다.

창문 dropout이 적용/미적용된 이미지는 Figure 6을 통해 모두 확인할 수 있다, 대부분의 네트워크는 침실에 창문을를 그리는 것을 대부분 잊어버리고 다른 객체로 대체한다.
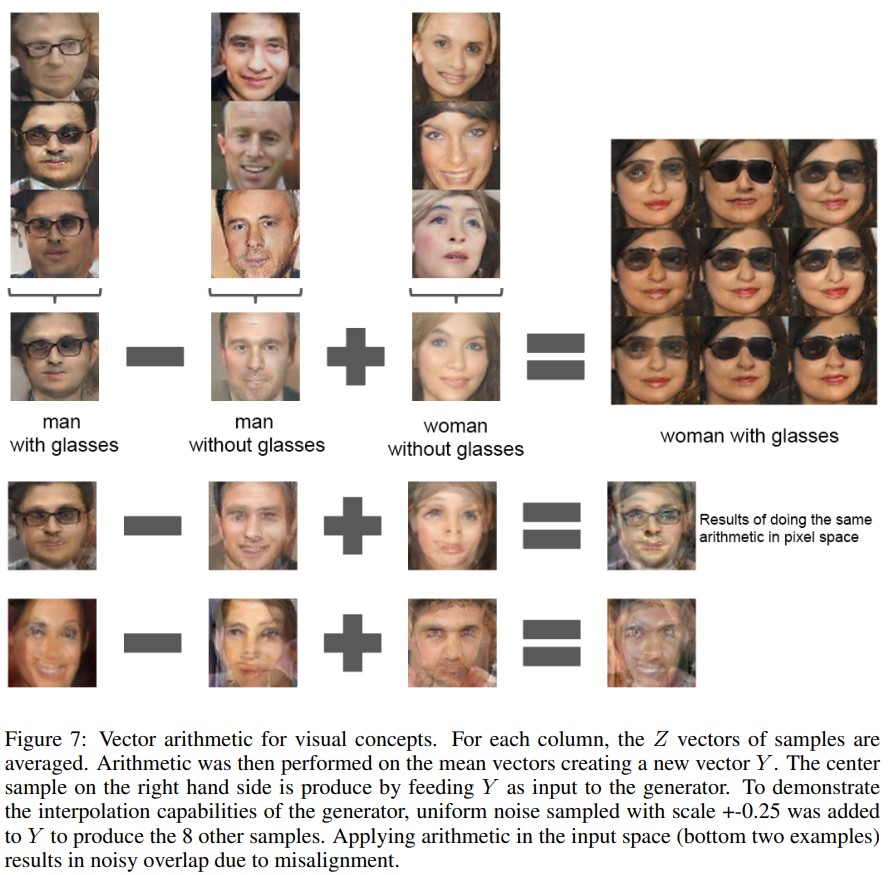
본 논문은 (Mikolov et al., 2013)(vector(”King”) - vector(”Man”) + vector(”Woman”) = nearest vector(“Queen”))에 기반하여 vector arithmetic에 대한 실험을 진행한다. 저자들은 generator의 Z 표현에 유사한 구조가 나타나는지 조사하는데, 시각적 개념에 대한 예제 샘플 세트의 Z 벡터에 대해 유사한 계산을 수행한다. 본 예제에서는 각 label에 대한 이미지 vector를 평균내 Z를 연산한 뒤 해당 Z값들을 합차 연산을 통해 “woman with glasses”라는 label에 대한 이미지를 생성한다. Single sample per concept를 대상으로 한 실험은 불안정했지만, 세 가지 examplars에 대해 Z 벡터를 평균하는 것은 안정적인 결과를 보여주었다. Figure 7에는 물체 조작, Figure 8에는 face pose modeling을 보인다.

6. Conclusion & Future Work
본 논문은 GAN을 훈련하기 위한 achitecture를 제안하고 adversarial network가 지도 학습 및 생성 모델링을 위해 이미지의 ‘good representation’을 학습한다는 것을 보인다. 하지만, 아직 모델이 더 오래 훈련되면 때때로 필터의 하위 집합을 단일 진동 모드로 축소하는 등의 불안정성이 여전히 남아 있으며 이를 해결 하는 것을 저자들은 future work로 두었다.
Subscribe via RSS