SAGAN : Self-Attention Generative Adversarial Networks
by JeongKee Lee, HyeBin Yoo
원본 논문 : Zhang, H., Goodfellow, I., Metaxas, D., & Odena, A. (2019, May). Self-attention generative adversarial networks. In International conference on machine learning (pp. 7354-7363). PMLR.
1. Introduction
컴퓨터 비전 분야에서 이미지 합성은 매우 중요한 문제입니다. deep convolutional network 기반 GAN은 image synthesis에서 매우 성공적이지만, convolution GAN에서 생성된 sample을 보면 multi-class dataset(예 : ImageNet)을 훈련할 때 모델링에 어려움이 있습니다. 예를 들어 ImageNet GAN 모델은 구조적 제약이 없는 (바다, 하늘과 같은) image의 synthesizing에는 탁월하지만, 기하학적 또는 구조적 패턴이 있는 (개의 발 같은) 경우에는 synthesizing 능력이 떨어집니다. 그 이유는 이전 모델이 다른 이미지 영역에 대한 종속성을 모델링하기 위해 convolution에 많이 의존한다는 것인데, 더 자세히 말하면 convolution operator는 local receptive field를 가지기 때문에 long range 의존성은 여러 convolution layer를 통과한 후에만 처리가 가능하기 때문입니다.

그림 출처 : https://simonezz.tistory.com/77
위의 그림을 보면 특정 window에서 convolution이 일어나기 때문에 다른 영역과의 결합, 종속성을 처리하려면 몇 개의 층을 지나야 합니다.
이는 다양한 이유로 long range 의존성에 대한 학습을 방해할 수 있습니다.즉, layer 수가 적은 model은 이러한 long range 종속성을 나타내지 못하고, 최적화 알고리즘은 이러한 의존성을 포착하기 위해 여러 layer를 세심하게 조정하는 매개변수 값을 발견하는 데 문제가 있을 수도 있으며, 이러한 매개변수화는 이전에 보지 못한 입력에 적용될 때 통계적으로 취약하고 실패할 확률이 높습니다. 또한, convolution kernel의 크기를 늘리면 네트워크의 표현 능력이 증가할 수 있지만, local convolution 구조를 사용하여 얻은 계산 및 통계 효율성마저 잃을 수 있습니다.
반면, self-attention은 long range 의존성 계산과 통계적인 면에서 균형감을 얻을 수 있습니다. Self-attention 모듈은 한 위치에서 모든 위치에서 feature들의 weighted sum으로 계산합니다. 여기서 가중치(또는 attention vector)는 적은 계산비용으로 계산됩니다.
이 논문에서는 self-attention 메커니즘을 convolution GAN에 도입하는 “SAGAN”을 제안합니다. self-attention 모듈은 convolution을 보완하고 먼 부분의 detail 모델링에 도움을 주며 이미지 영역 사이에서 multi-level 의존성에도 도움을 줄 수 있습니다.(=이미지 영역을 가로질러 long range, multi-level 의존성 모델링하는데 도움을 줌!)
결과적으로 self-attention을 갖춘 generator는 모든 위치에서 작은 detail이 멀리 있는 detail과 조화되는 이미지를 그릴 수 있고, discriminator는 전체 이미지 구조에서 더 정확하겍 복잡한 기하학적인 제한들을 강화시킵니다. 즉, SAGAN의 discriminator는 이런 제한들을 통해 더 가짜이미지를 잘 구분해내서 결국에는 generator가 기하학적인 패턴을 더 잘 잡아내는 이미지를 생성하도록 한다고 생각하시면 됩니다.
저자는 self-attention외에도 network conditioning과 GAN 성능과 관련된 conditioning이 잘 된 generator가 더 나은 성능을 보인다는 최근의 insights를 통합하였습니다. 이 논문에서는 discriminator에만 적용되었던 spectral normalization 기술을 사용하여 GAN generator에도 적용할 것을 제안합니다.
제안된 self-attention 메커니즘과 안정화 기수의 효과를 검증하기 위해 ImageNet dataset에 대한 실험을 수행하였습니다. SAGAN은 이미지 합성 분야에서 이전 논문의 수준을 훨씬 뛰어넘는 성능을 보여줍니다. 기존의 가장 좋은 inception score를 36.8에서 52.52로 올렸으며, Fréchet Inception distance는 27.62 에서 18.65로 줄였습니다. 어텐션 층의 시각화를 통해 generator가 고정된 형태의 지역적 영역보다 물체의 모양과 일치하는 주변의 정보를 활용하는 것을 볼 수 있습니다.
contribution
- long range, multi-level 의존성 모델링을 위해 GAN에 self-attention 모듈 사용
- 기존에 discriminator에만 사용되었던 spectral normalization을 generator에도 적용하여 GAN의 성능 upgrade
2. Related Work
Generative Adversarial Networks.
GAN은 image to image translation, text to image translation을 포함한 다양한 이미지 생성 작업에서 큰 성공을 거두었습니다. 그래도 GAN의 훈련은 여전히 불안정하고 hyperparameter에 민감합니다. 그래서 dynamics, regularization 방법 추가, hyeristic tricks 추가를 하는 등 새로운 network architecture를 설계, 학습 목표를 수정하여 GAN training dynamics를 안정화, 샘플의 다양성을 개선하기 위해 여러 시도를 하였습니다. 최근에는 discriminator 함수의 Lipschitz 상수를 제한하기 위해 discriminator에서 가중치 행렬의 spectral normalization을 제한할 것을 제안하였고, projection 기반 discriminator와 결합된 spectrally normalized model은 ImageNet에서 클래스 조건부 이미지 생성에서 큰 성능 향상을 보였습니다.
여기서 projection discriminator는 아래 그림의 (d)에 해당합니다.
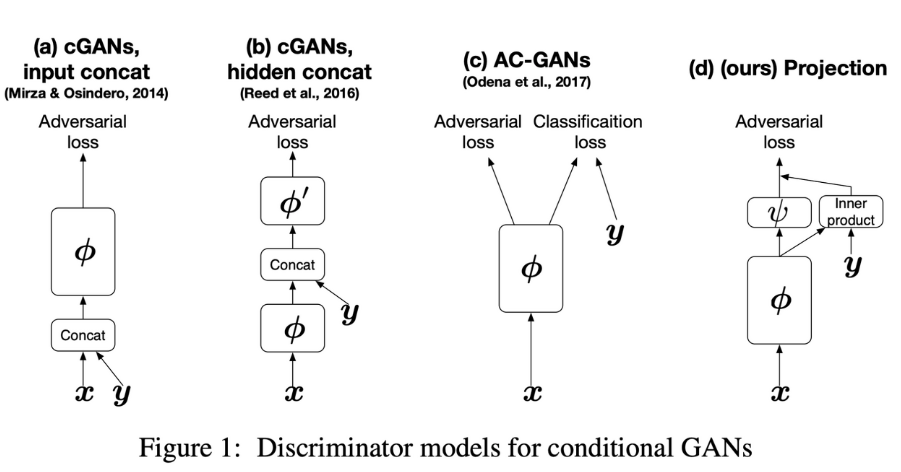
그림출처 : https://arxiv.org/abs/1802.05637
간단하게 설명하자면 discriminator가 image가 진짜인지 가짜인지 분류할 때 projection 과정을 통과하여 분류되는 방법입니다. 자세한 사항은 이 링크를 참고하시면 됩니다.
Attention Models.
최근 attention 메커니즘은 global 종속성을 포착해야 하는 모델의 필수적인 부분이 되었습니다. 특히 self-attention(intra-attention이라고도 하는)은 같은 sequence 내의 모든 position에 주의를 기울여 한 위치에서의 response를 계산합니다.
아래 그림은 Transformer의 모델 구조이고, self-attention은 트랜스포머의 핵심입니다.
![]()
그림 출처 : https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Transformer 논문(Attention is All You Need)에서 저자는 기계번역 모델이 오직 self-attention 모델만 사용함으로써 SOTA 수준의 결과를 이룬것을 보여주었습니다. 다른 논문에서는 Image Transformer 모델을 제안했는데, self-attention을 이미지 생성을 위해 autoregressive 모델에 추가하기 위함이었습니다. 또 다른 논문에서는 self-attention을 video sequence에서 spatial-temporal dependency를 모델링 하기 위해 non-local operation으로 형태화하였습니다. 이 모든 것은 global함을 갖기 위해 attention을 적용한 것입니다.
이러한 진전에도 불구하고 GAN에서의 self-attention은 아직 탐구되지 않았습니다. SAGAN은 이미지의 내부 표현 내에서 global 장거리 종속성을 효율적으로 찾는 방법을 self-attention 메커니즘을 이용하여 훈련합니다.
3. Self-Attention Generative Adversarial Networks
이미지 생성을 위한 대부분의 GAN 기반 모델은 convolution layer를 사용합니다. convolution은 이웃한 주변의 정보를 사용합니다. 이는 convolution layer만을 사용하는 것이 이미지에서 long-range dependeincies를 모델링하는데에 비효율적입니다. 저자들은 generator와 discriminator가 공간적으로 멀리 떨어진 영역간의 관계를 효율적으로 모델링할 수 있도록, GAN 프레임워크에 self-attention 개념을 넣기 위해 non-local network1를 적용합니다. 이 방법을 저자들은 Self-Attention Generative Adversarial Networks(SAGAN)이라 칭합니다.(Figure 2 참조)
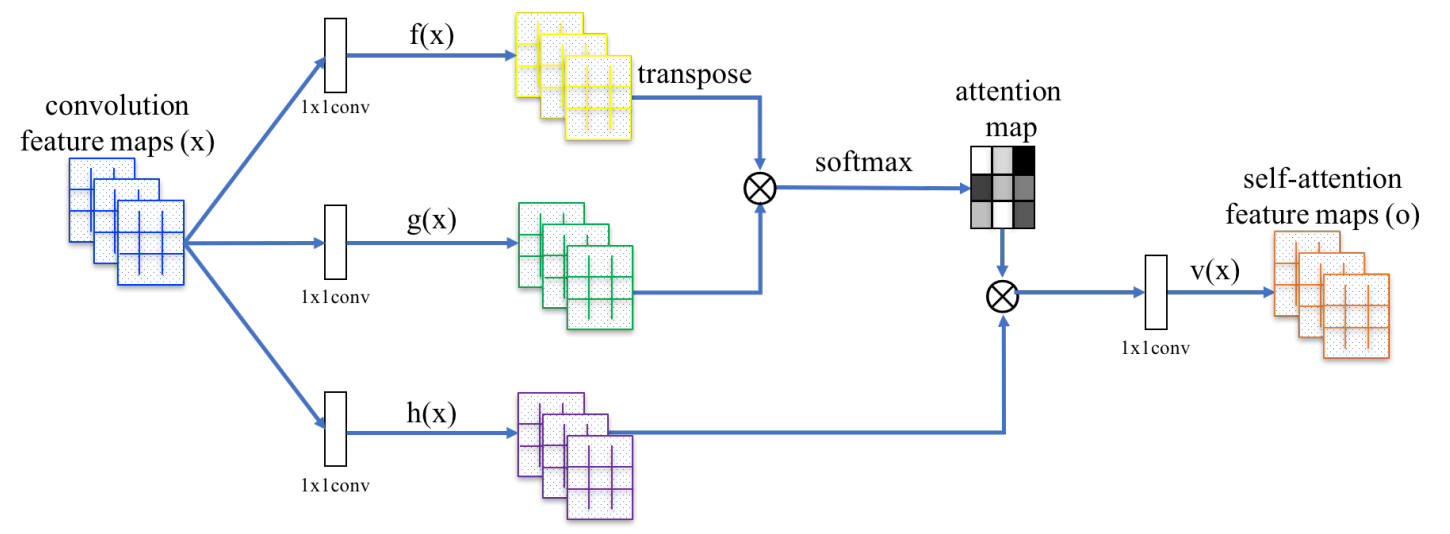
Figure 2 SAGAN의 제안된 셀프-어텐션 모듈
이전 hidden layer으로 나온 이미지의 특징 벡터 $x \in \mathbb{R^{C \times N}}$는 먼저 attention을 계산하기 위해 2개의 feature space $f, g$로 변환됩니다. 여기서 $f(x)=W_fx, \space g(x)=W_gx$입니다. 변환된 이후 아래 식을 통해 attention map을 생성합니다.
\[\beta_{j,i}=\frac{\exp(s_{ij})}{\sum^N_{i=1}\exp(s_{ij})}, \space where \space s_{ij}=f(x_i)^Tg(x_j)\]$\beta_{j,i}$는 $j$번째 영역을 합성 할 때 $i$번째 위치에 대한 attention을 의미합니다. 여기서 $C$는 채널의 수이며 $N$은 이전 hidden layer로부터 feature location의 수 입니다. attention의 출력은 $o = (o_1, \space o_2, \space \dots, \space o_j, \space \dots, \space o_N) \in \mathbb{R}^{C \times N}$ 입니다.
\[o_j = v\Bigg(\sum^N_{i=1}\beta_{j,i}h(x_i)\Bigg), \space h(x_i)=W_hx_i, \space v(x_i)=W_vx_i\]위의 공식에서, $W_g, W_f, W_h$ 그리고 $W_v \in \mathbb{R}^{\overline{C} \times C}$ 는 학습가능한 weight 행렬이며 1X1 convolution으로 구현되었습니다.
저자들은 ImageNet에서 $\overline{C}$의 채널 수를 $C/k$로 줄일 때 큰 성능 하락이 없었다고 합니다. 이에 따라, 메모리 효율성을 위해 저자들은 모든 실험에서 $k=8(i.e., \overline{C}=C/8)$을 선택하였습니다.
추가적으로, attention의 출력층에 scale parameter를 곱하고 뒤에 input feature를 더하였습니다. 최종 출력은 아래식과 같습니다.
\[y_i= \gamma o_i+x_i\]여기서 $\gamma$는 학습가능한 스칼라값이며 0으로 초기화했다가 $\gamma$이 네트워크가 먼저 local 이웃의 cues에 의존할 수 있게 하여 점차적으로 non-local cues에 더 많은 비중을 두는 법을 배우게 됩니다. 이렇게 하는 이유를 직관적으로 설명하면 쉬운 일을 먼저 배운 다음 점차적으로 일의 복잡성을 증가시키기 위함입니다.
SAGAN에서는 제안된 attention 모듈이 generator와 discriminator 둘 다 적용됩니다. generator와 discriminator는 번갈아가며 GAN hinge loss function을 최소화하는 방향으로 훈련됩니다.
\[\begin{align*} L_D= &-\mathbb{E}_{(x,y) \sim p_{data}}[\min(0, -1+D(x,y))] \\ &-\mathbb{E}_{z\sim p_{z}, y \sim p_{data}}[\min(0, -1-D(G(z),y))] \\ L_G= &-\mathbb{E}_{z \sim p_{z}, {y \sim p_{data}}}D(G(z), y) \end{align*}\]self-attention을 실제 코드에 적용하면 다음과 같습니다.
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
4. Techniques to Stabilize the Training of GANs
저자들은 GAN의 학습을 안정화시키기위해 두 가지 테크닉을 조사했습니다. 첫째, 저자들은 generator에 spectral normalization(SN)을 사용했습니다. 둘째, 규제된 discriminator의 느린 학습 속도를 해결하기 위해 효과적이며 선호되는 방법인 Two-Timescale Update Rule(TTUR)을 사용했습니다.
4.1. Spectral normalization for both generator and discriminator
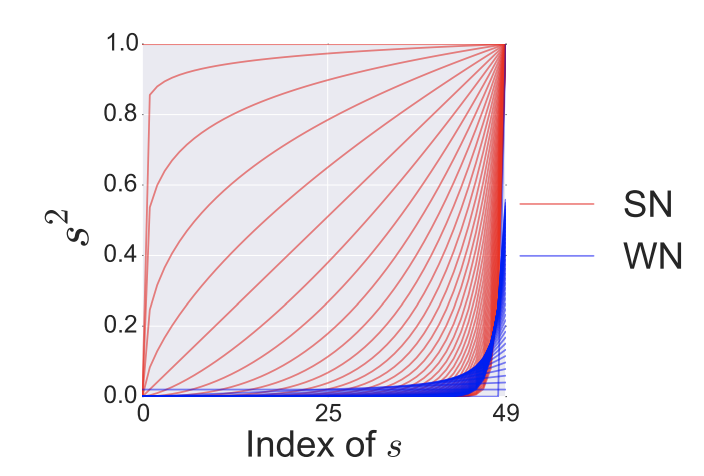 먼저, 스펙트럴 정규화(SN)에 대해 간단히 설명을 하겠습니다. SN은 각 레이어 $g:h_{in} \rightarrow h_{out}$의 스펙트럴 놈을 제한함으로써 discriminator $f$의 립시츠 상수를 제어합니다. 립시츠 놈 $\Vert g \Vert_{Lip}$은 $\sup_h \sigma(\nabla g(h))$와 동일합니다. 여기서, $\sigma(a)$ 은 행렬 $A$의 스펙트럴 놈입니다. ($A$의 $L_2$ 행렬 놈):
먼저, 스펙트럴 정규화(SN)에 대해 간단히 설명을 하겠습니다. SN은 각 레이어 $g:h_{in} \rightarrow h_{out}$의 스펙트럴 놈을 제한함으로써 discriminator $f$의 립시츠 상수를 제어합니다. 립시츠 놈 $\Vert g \Vert_{Lip}$은 $\sup_h \sigma(\nabla g(h))$와 동일합니다. 여기서, $\sigma(a)$ 은 행렬 $A$의 스펙트럴 놈입니다. ($A$의 $L_2$ 행렬 놈):
스펙트럴 놈은 $A$의 가장 큰 특이값과 같습니다. 그러므로, 선형 레이어 $g(h)=Wh$의 대한 놈은 $\Vert g \Vert_{Lip}=\sup_h\sigma(\nabla g(h))=\sup_h\sigma(W)=\sigma(W)$과 같이 주어집니다. SN은 weight 행렬 $W$의 스펙트럴 놈을 정규화합니다. 이것은 립시츠 상수 $\sigma(W)=1$을 만족합니다. :
\[\overline{W}_{SN}(W)=W/\sigma(W)\]다시 말해, 각 레이어의 SN을 제한함으로써 discriminator의 Lipschitz상수를 제한합니다. 다른 정규화 테크닉과 비교해서, SN은 추가적인 hyperparameter 튜닝을 요구하지 않습니다.(모든 weight layer를 1로 지정하여도 잘 동작함) 더욱이, computational cost 또한 상대적으로 적습니다.
저자들은 generator 또한 SN을 사용하는 것이 좋다고 합니다. generator에게 어떠한 조건을 거는 것은 GAN의 성능에 매우 중요한 causal factor이기 때문입니다. SN은 parameter 크기의 증가를 막아주고, 비정상적인 gradient를 피할 수 있게 합니다. 저자들은 경험적으로 generator와 discriminator 둘 다에 SN을 적용하는 것이 generator를 업데이트 할 때 더 적게 discriminator를 업데이트 해도 된다는 점을 발견합니다. 이러한 접근은 또한 더 안정적으로 학습이 가능하게 합니다.
다음은 generator에서 SN을 적용한 코드입니다. SN을 적용한 부분만 일부 발췌하였습니다.
repeat_num = int(np.log2(self.imsize)) - 3
mult = 2 ** repeat_num # 8
layer1.append(SpectralNorm(nn.ConvTranspose2d(z_dim, conv_dim * mult, 4)))
layer1.append(nn.BatchNorm2d(conv_dim * mult))
layer1.append(nn.ReLU())
curr_dim = conv_dim * mult
layer2.append(SpectralNorm(nn.ConvTranspose2d(curr_dim, int(curr_dim / 2), 4, 2, 1)))
layer2.append(nn.BatchNorm2d(int(curr_dim / 2)))
layer2.append(nn.ReLU())
curr_dim = int(curr_dim / 2)
layer3.append(SpectralNorm(nn.ConvTranspose2d(curr_dim, int(curr_dim / 2), 4, 2, 1)))
layer3.append(nn.BatchNorm2d(int(curr_dim / 2)))
layer3.append(nn.ReLU())
if self.imsize == 64:
layer4 = []
curr_dim = int(curr_dim / 2)
layer4.append(SpectralNorm(nn.ConvTranspose2d(curr_dim, int(curr_dim / 2), 4, 2, 1)))
layer4.append(nn.BatchNorm2d(int(curr_dim / 2)))
layer4.append(nn.ReLU())
self.l4 = nn.Sequential(*layer4)
curr_dim = int(curr_dim / 2)
다음은 discriminator에 SN을 적용한 코드입니다. 이 역시 SN을 사용한 부분만 일부 발췌하였습니다.
layer1.append(SpectralNorm(nn.Conv2d(3, conv_dim, 4, 2, 1)))
layer1.append(nn.LeakyReLU(0.1))
curr_dim = conv_dim
layer2.append(SpectralNorm(nn.Conv2d(curr_dim, curr_dim * 2, 4, 2, 1)))
layer2.append(nn.LeakyReLU(0.1))
curr_dim = curr_dim * 2
layer3.append(SpectralNorm(nn.Conv2d(curr_dim, curr_dim * 2, 4, 2, 1)))
layer3.append(nn.LeakyReLU(0.1))
curr_dim = curr_dim * 2
if self.imsize == 64:
layer4 = []
layer4.append(SpectralNorm(nn.Conv2d(curr_dim, curr_dim * 2, 4, 2, 1)))
layer4.append(nn.LeakyReLU(0.1))
self.l4 = nn.Sequential(*layer4)
curr_dim = curr_dim*2
generator와 비교하였을 때 제일 눈에 띄는 부분은 batch normalization을 사용했냐 안했냐 입니다. generator에서는 사용을 하였지만, discriminator에서는 사용하지 않은 것을 알 수 있습니다.
4.2. Imbalanced learning rate for generator and discriminator updates
Discriminator의 정규화는 종종 GAN의 학습 속도를 느리게 합니다. 실제로, 이전 연구에서 일반적으로 정규화된 discriminator를 사용하는 방법은 generator가 한 번 업데이트 될 때 더 많은 업데이트가 필요했습니다. 이 방법과는 다르게, 서로 다른 학습률(TTUR)을 적용하여 generator와 discriminator를 학습하는 것도 제안되곤 했습니다.(generator 한 번 업데이트 시 discriminator 5번 업데이트 하는 방법 등) 저자들은 이러한 점을 활용하여 정규화된 discriminator에서의 느린 학습의 문제를 해결하기 위해 TTUR2을 사용합니다. 이 방법을 사용함으로써, 똑같은 시간 내에 더 좋은 결과를 생성할 수 있었습니다.
5. Experiments
이 논문에서 제안한 모델을 평가하기 위해 LSVRC2012(ImageNet) dataset에 대해 실험하였습니다 5.1에서는 GAN의 훈련을 안정화하기 위해 제안뒨 두 가지 기술의 효율성을 평가하기 위해 설계된 실험을 제시하고, 5.2에서는 self-attention 메커니즘을, 5.3에서는 이미지 생성 작업에 대한 최신 방법과 비교하였습니다.
Evaluation metrics.
평가지표로는 Inception Score와 Fréchet Inception distance(FID)를 사용하였습니다.
Inception Score는 conditional class 분포와 marginal class 분포간의 KL divergence를 계산합니다. 더 높은 inception score는 더 좋은 이미지 품질을 의미합니다. Inception score를 평가지표로 사용한 이유는 이전의 많은 연구에서 널리 사용되었기 때문입니다. 하지만, inception score에는 심각한 한계가 있습니다. Inception score는 주로 모델이 특정 클래스에 잘 속할 수 있는 샘플을 생성하고, 모델이 많은 클래스에서 샘플을 생성하도록 하기 위한 것이지, detail이나 클래스 내 다양성의 현실성을 평가할 필요는 없습니다.
FID는 보다 원칙적이고 포괄적인 메트릭스 입니다. 이는 생성된 샘플의 현실성과 변동성을 평가할 때 인간의 평가와 더 일치합니다. FID는 생성된 이미지와 Inception-v3 네트워크 feature map에서 실제 이미지 사이의 Wasserstein-2거리를 계산합니다. 전체 데이터 분포(즉, ImageNet의 모든 100개 이미지 클래스)에 대해 계산된 FID 외에도 생성된 이미지와 각 클래스 내 데이터 세트 이미지 사이의 FID를 계산하고, intra FID라고도 합니다. FID 및 intra FID값은 낮을수록 실제와 가깝다는 것입니다.
모든 실험에서 50k의 샘플은 각 모델에 대해 random하게 생성되어 Inception score, FID 및 intra FID를 계산합니다.
Network structures and implementation details.
모든 SAGAN 모델은 128x128 크기의 이미지를 생성하도록 훈련되었습니다. 일단 기본적으로 generator와 discriminator 모두 SN을 적용하였습니다. 또한, conditional batch 정규화를 generator와 discriminator의 projection에 사용하였습니다. 모든 모델은 $\beta_1=0$으로 $\beta_2=0.9$로 설정한 Adam optimizer를 사용하였습니다. 기본적으로, discriminator의 학습률은 0.0004이고 generator는 0.001입니다.
5.1. Evaluating the proposed stabilization techniques
5.1에서는 generator에 SN을 적용하고 TTUR을 활용하는 방법의 효율성을 평가하기 위한 실험을 수행합니다.

Figure 3

Figure 4
baseline 모델은 SN은 discriminator에만 사용되었습니다. Discriminator와 generator에 대해 1:1 update 훈련하면 그림 3의 왼쪽 하위 그림과 같이 훈련이 매우 불안정해지는데, 이는 훈련 초기의 mode collapse를 나타냅니다. 예를 들어 그림 4의 왼쪽 상단 하위 그림은 10k번째 iteration에서 기준 모델에 의해 랜덤하게 생성된 일부 이미지를 보여줍니다.
원래의 baseline 모델에서는 D와 G를 5:1 불균형 update를 사용하여 이러한 불안정한 훈련 동작을 크게 완화하였지만, 1:1 균형 update로 안정적으로 훈련하는 기능은 모델의 훈련 속도를 향상시키기에는 좋습니다. 그래서 이 논문에서 제안된 기술을 사용하면 동일한 wall-clock 시간에서 모델이 더 나은 결과를 생성할 수 있습니다. 이를 감안하면 generator와 discriminator에 적합한 업데이트 비율을 검색할 필요가 없습니다. 그림 3의 중간 하위 그림에서 볼 수 있듯이 generator와 discriminator 모두에 SN을 추가하면 1:1 균형 update로 훈련된 경우(SN on G/D)에도 모델이 크게 안정화됩니다.
하지만 샘플의 품질은 훈련중에 무조건적으로 향상되지 않습니다. 예를 들어 FID 및 Inception score로 측정한 이미지 품질은 260k번째 iteration에서 떨어지기 시작합니다. 그런데, D와 G를 훈련시키기 위해 불균형 학습률을 적용할 때 이 논문에서 제안된 모델 “SN on G/D + TTUR”에 의해 생성된 이미지 품질은 전체 훈련 과정에서 계속 향상됩니다. 그림 3과 그림 4에서 볼 수 있듯이 백만번의 훈련 iteration동안 샘플 품질이나 FID, Inception score에서 유의미할 정도의 감소가 없습니다. 따라서 정량적 결과와 질적 결과 모두 안정화 기술의 효과를 보여줍니다.
5.2. Self-attention mechanism

Table 1.
제안된 self-attention 메커니즘의 효과를 탐색하기 위해 generator와 discriminator의 다른 단계에 self-attention 메커니즘을 추가하여 여러 SAGAN의 모델을 구축한 결과입니다.
표 1에서는 SAGAN 모델에서 feature map의 크기가 32와 64에서의 결과가 ($feat_{32}$ and $feat_{64}$) 크기가 8과 16의 결과보다($feat_{8}$ 및 $feat_{16}$) 더 나은 성능을 달성하는 것을 확인할 수 있습니다. 예를 들어 “SAGAN, $feat_{8}$”모델의 FID는 “SAGAN, $feat_{32}$”에 비해 22.98에서 18.28로 향상되었습니다. 그 이유는 self-attention이 더 많은 evidence를 받고 더 큰 feature map을 가진 condition을 선택할 수 있는 더 많은 자유를 누리기 때문입니다. 즉, 큰 feature map의 경우 convolution에 보완적입니다.
그러나 작은 feature map(예 : 8x8)에 대한 종속성을 모델링할 때 local convolution과 유사한 역할을 합니다. 이는 attention 메커니즘이 generator와 discriminator에 더 많은 권한을 제공하여 feature map에서 장거리 종속성을 직접 모델링한다는 것을 보여줍니다. 또한 SAGAN과 attention이 없는 baseline 모델의 비교(표1의 두번째 열)은 제안된 self-attention 메커니즘의 효율성을 추가로 보여주고 있습니다.
또한, 동일한 수의 매개변수를 가진 residual block과 비교할 때 self-attention block도 더 나은 결과를 얻습니다. 표 1의 오른쪽 열에서 8x8 feature map에서 self-attention을 residual block으로 교체하면 훈련이 안정적이지 않아 성능이 크게 저하되는 것을 볼 수 있습니다.(예 : FID가 22.98에서 42.13으로 증가) 훈련이 순조롭게 진행되는 경우에도 self-attention block을 residual block으로 교체하면 여전히 FID 및 Inception score 측면에서 더 나쁜 결과를 초래하는 것 또한 볼 수 있습니다.(예 : featre map 32x32의 18.28 vs 27.33) 이 비교는 SAGAN을 사용하여 제공되는 성능 향상이 단순히 모델 깊이와 용량 증가때문이 아님을 보여줍니다.
generation 과정에서 학습한 내용을 더 잘 이해하기 위해 다양한 이미지에 대해 SAGAN에서 generator의 attention weight를 시각화하였습니다. attention map의 일부 샘플 이미지가 밑의 그림에서 확인할 수 있습니다.

Figure 1 SAGAN은 일돤된 객체/시나리오를 생성하기 위해 고정된 모양의 local region이 아닌 이미지의 먼 부분에 있는 보완적인 기능을 활용하여 이미지를 생성합니다. 각 행에서 첫 번째 이미지는 색상으로 구분된 점으로 5개의 대표적인 query 위치를 보여줍니다. 다른 5개의 이미지는 해당 query 위치에 대한 attention map이며, 가장 많이 attend한 region을 요약하는 해당 색상 코드 화살표로 나타내고 있습니다.

Figure 5 그림 5는 각 쿼리에대해한 attention map으로, query에 대해서 가장 집중해서 보는 지역을 보여주고 있습니다. 여기서는 attention을 사용한 마지막 generation layer의 attention map을 시각화하였습니다. 각 셀에서 첫 번째 이미지는 색상으로 구분된 점이 있는 세 개의 대표적은 query 위치를 보여줍니다. 다른 3개 이미지는 해당 query 위치에 대한 attention map이며 해당하는 색상으로 구분된 화살표는 가장 많이 attend한 region을 나타냅니다. 이 그림을 통해 네트워크가 공간적 인접성보다는 색상과 texture의 유사성에 따라 attention을 할당하는 법을 배운다는 것을 관찰할 수 있습니다.(왼쪽 상단 셀) 또한, 일부 query 포인트는 공간적 위치에서는 매우 가깝지만 왼쪽 하단 셀에 표시된 것처럼 attention map이 다를 수 있습니다. SAGAN은 오른쪽 상단 셀에서 볼 수 있듯이 다리가 명확하게 분리된 개를 그릴 수 있음을 보여줍니다. 여기서 파란색 query 포인트는 관절 영역의 구조를 올바르게 얻는 데 도움이 된다는 것을 보여줍니다.
5.3. Comparison with the state-of-the-art
이 섹션에서는 SAGAN을 ImageNet에서 클래스 조건부 이미지 생성을 위한 최신 GAN모델과 비교합니다. 표 2에서 볼 수 있듯이 SAGAN은 IntraFID와 FID에서 최고의 Inception score를 달성합니다. SAGAN은 publish된 Inception 점수를 36.8에서 52.52로 크게 향상시킵니다. SAGAN에 의해 달성된 더 낮은 FID(18.65) 및 인트라 FID(83.7)는 또한 SAGAN이 이미지 영역 간의 장거리 종속성을 모델링하기 위해 self-attention 모듈을 사용하여 원본 이미지 분포를 더 잘 근사할 수 있음을 나타냅니다.

Table 2
그림 6은 ImageNet의 대표적인 클래스에 대한 몇 가지 비교 결과와 생성된 이미지를 보여줍니다.

Figure 6
그림 6에서 SAGAN이 금붕어와 Saint Bernard와 같은 복잡한 기하학적 또는 구조적 패턴을 가진 이미지 클래스를 합성하기 위해 최첨단 GAN모델보다 더 나은 성능(즉, 더 낮은 인트라 FID)을 달성한다는 것을 확인할 수 있습니다. 구조적 제약이 거의 없는 클래스(기하학보다 texture로 더 많이 구별되는 계곡, 돌담 및 산호 곰팡이)의 경우 SAGAN은 baseline에 비해 우월하지는 못합니다. 다시 말하면, 그 이유는 SAGAN의 self-attention이 기하학적 또는 구조적 패턴에서 일관되게 발생하는 장거리 저역 수준 종속성을 캡쳐하기 위한 convolution에 보완적이지만 간단한 텍스처에 대한 종속성을 모델링할 때 로컬 convolution과 유사한 역할을 하기 때문입니다.
6. Conclusion
이 논문에서 저자들은 셀프-어텐션 메카니즘을 GAN 프레임워크에 결합한 Self-Attention Generative Adversarial Networks(SAGANs)를 제안합니다. 셀프-에텐션 모듈은 long-range dependencies를 모델링하는데에 효과적이었습니다. 게다가, 스펙트럴 정규화을 generator에 적용하여 GAN 학습을 안정화시카고 TTUR을 통해 규제된 discriminator의 학습 속도를 증가시켰습니다. SAGAN은 ImageNet의 class-conditional 이미지 생성에서 state-of-the art를 달성하였습니다.
7. Future Work
Improved Transformer for High-Resolution GANs
Transformer의 핵심 아이디어인 self-attention을 이용하여 장거리 종속성 문제는 해결하였지만, 고화질 생성이 어렵다는 단점에서 아이디어를 얻은 논문입니다. 우선 생성 프로세스의 저해상도 단계에서 standard global self-attention을 multi-axis blocked self-attention로 대체하여 local attention과 gloabl attention의 효율적인 mixture를 가능하게 합니다. 이후 고해상도 단계에서 implicit nueral function을 연상시키는 MLP만 유지하며 self-attention을 drop하여 고해상도의 결과를 생성할 수 있도록 하는 것이 논문의 핵심 아이디어입니다.
ViTGAN: Training GANs with Vision Transformers
self-attention이 transformer의 핵심 아이디어인데, 여기서는 self-attention 모듈 뿐 아니라 기존 transformer를 발전시킨 vision transformer를 통째로 GAN과 융합한 논문입니다. 이 논문에서는 GAN에 self-attention을 융합하였을 때 생긴 훈련의 불안전성을 Vision Transformers를 이용한 새로운 정규화기법을 이용하여 해결하였다고 말하고 있습니다.
Reverse Footnote
Subscribe via RSS