PixelCNN++
by Huigyu Yang, Ju Hun Lee
- Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik P Kingma. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517, 2017
- Introduction
- Modifications
- Discretized Logistic Mixture Likelihood
- Conditioning on Whole Pixels
- Downsampling Versus Dilated Convolution
- Adding Short-cut Connections
- Regularization Using Dropout
- Unconditional Generation (CIFAR10)
- From PixelCNN to PixelSNAIL
- Concusion
Introduction
2016년 당시에 likelihood-based autoregressive 생성 모델이 유행했습니다. 그중에서도 log-likelihood metric 측면에서 SOTA인 PixelCNN이 주목받았습니다. PixelCNN는 $p(x_i|x_{<_i})$ 분포를 CNN으로 학습합니다. 기본적으로 PixelCNN은 전 픽셀들의 정보를 convolutional kernel를 사용해서 정보를 수집하게 되고, “blind spot”을 horizontal & vertical stack/filter로 해결하게 됐습니다.
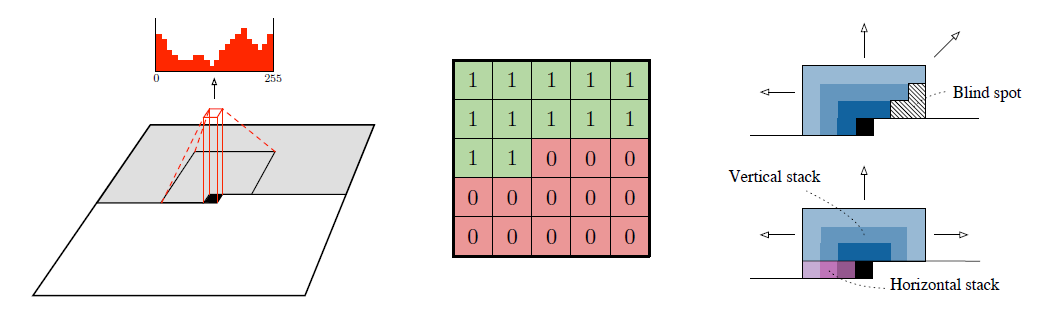
PixelCNN에 관한 자세한 설명은 여기서 확인하실 수 있습니다.저자들은 이런 PixelCNN을 더 개선해서 성능이 더 높은 PixelCNN++를 제안합니다. 각 문제점과 개선 방법을 소개하겠습니다.
Discretized Logistic Mixture Likelihood
PixelCNN에서 하나의 pixel 값을 예측하는 것은 즉 0~255 값을 softmax을 이용해 classification으로 접근한다 (pixel 값마다 하나의 클래스). 그래서 class들간의 관계가 없는 상태로 학습이 시작하기 때문에 생성을 위한 학습 외에 그 관계를 먼저 학습해야 한다는 점도 발생합니다.

PixelCNN++에서는 softmax을 사용하는 대신 예측되는 pixel 값의 분포 파라미터를 출력하게끔 설정합니다. 이런 파라미터가 주어지면, 쉽게 심플링이 가능하게 됩니다. 여기서 좀 더 복잡한 분포를 출력할 수 있도록 mixture of distribution을 사용하게 됩니다. 좀 더 정확하게 logistic 분포의 조합(mixture)를 사용합니다.
.png)
저희가 계산해야 할 부분은 모델이 출력한 logistic 분포의 파라미터로 정답인 x픽셀 값을 예측할 확률을 구하는 것입니다. 그럼 모델이 출력한 분포값이 나올 부분을 적분하면 됩니다. 적분을 구하기 위해 저희는 logistic 분포의 CDF인 sigmoid를 사용합니다.
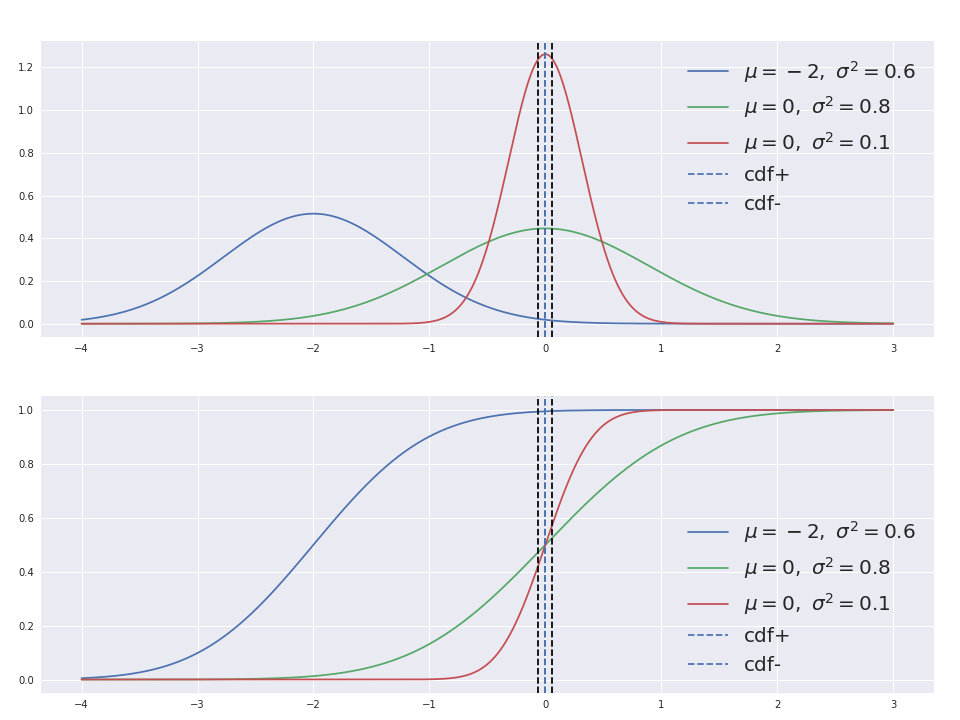
식(1)은 mixture of logistic distribution식이다. pi로 각 logistic distribution의 기여도를 결정하고, 각 logistic 분포의 파라미터 mu와 scale이 존재합니다. 식(2)를 이해하기 위해서 그래프를 가져와봤습니다. 더 심플하게 설명하기 위해 mixture가 아닌 simple logistic으로 설명해보겠습니다. 윗 그래프는 분포로 Logistic PDF이고 아래는 각자 해당되는 CDF이고 (variance를 scale로 해석해주시면 됩니다), CDF+과 CDF-는 픽셀 구간(PixelCNN 같은 경우 +0.5와 -0.5)입니다.보시다시피 빨간색 분포에서 CDF+와 CDF-이 CDF 함수를 만나는 지점들이 간격이 제일 큽니다. 확률적으로 해석하면 0에 샘플링될 확률이 셋 중에서 제일 높다는 뜻입니다. 그럼 이젠 식(2)를 둘러보겠습니다. 보시다시피 X = mu = 0일 때 빨간 그래프 상황이 이루어지고 그럴 경우에 P(X)가 극대화됩니다. P(x)에 -log만 추가해주면 로스 함수로 만들고 학습이 가능합니다. 이와 함께 분포의 weight값 pi도 학습하게 됩니다.
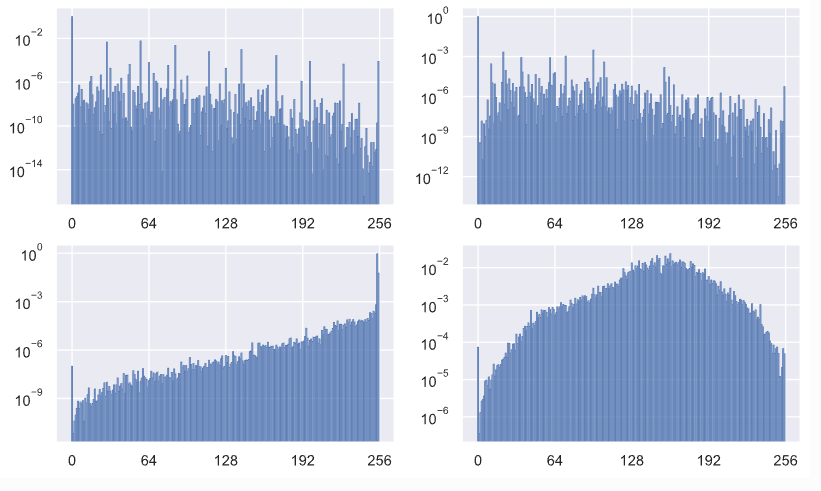
Discretized Logistic Mixture Likelihood을 사용한 점이 이 논문의 핵심이 됩니다. 저희가 모델링하는 대상 이미지는 natural하고 continuous한 분포를 따르는데, softmax을 사용했을 때 그런 분포를 학습하는 게 어렵습니다. 아래 분포는 모두 랜덤 픽셀값 생성 분포이고, 상단에는 softmax로 학습한 것이고 하단은 mixture of logistic distributions을 사용했습니다. Logistic distribution을 사용한 버전이 실제 데이터 분포를 더 반영하고 있다는 것이 바로 확인됩니다.
Conditioning on Whole Pixels
기존 PixelCNN에서 각 RGB값을 생성할 때 autoregressive하게 factorized하게 생성합니다. PixelCNN++에서는 RGB를 autoregressive하게 생성하지만 모두 동일한 feature map을 사용하고 서로 linear한 관계를 갖게 설정했습니다. 그 뜻은, green 과 red, 또는 blue와 green,red의 관계를 coefficient로 표현이 가능하다는 것입니다. 그럼 모델이 실질적으로 출력하는 값들은 mixture logistic distribution의 파라미터들과 linear coefficients $\alpha$ , $\beta$ 와 $\gamma$ 입니다.
![]()
이 부분을 코드로 구현을 확인할 때 다음과 같습니다. means. log_scales, coeff는 모델이 출력하는 파라미터입니다. 먼저 mean을 log_scales로 scaling해주고, 각 채널을 생성할 때, 생성된 채널과 coeff로 곱해주면서 다음 채널을 출력하는 것을 확인할 수 있습니다.
![]()
Downsampling Versus Dilated Convolution
기존 PixelCNN에서는 비교적 receptive field이 작은 convolution을 사용합니다. long dependency 관계를 포착하기 위해 인풋을 dilated convolution으로 압축하면서 receptive field를 늘립니다 (그런 후 feature map을 다시 spatially 키워줍니다). 하지만 computation cost 측면에서 convolution의 stride를 키워주면서 인풋을 압축하는 게 더 유리합니다. 따라서 여기는 dilated convolution을 사용하지 않고 stride가 더 높은 convolution을 사용합니다.

https://ai.stackexchange.com/questions/5991/is-my-understanding-of-how-the-convolution-with-stride-2-works-in-this-example-c
</p>
#### Adding Short-cut Connections
Stride가 높을수록 정보 손실이 일어날 수 있습니다. 이 점을 보완하기 위해서 short-cut connection을 사용합니다 (ResNet layer 1과 6, 2와 5, 3과 4에 short-cut connection).
그럼 실제로 PixelCNN의 receptive field는 어떻게 작동될까요?
아래 그림을 보시면 중앙 픽셀에 생성에 있어서 전 픽셀들의 영향을 계산합니다. Random initialization에서 각 픽셀의 gradient를 계산하고 값이 0.001보다 클 경우 칠해줍니다. 보시다시피 PixelCNN 비해 PixelCNN++가 더 큰 receptive field를 갖고 있습니다. 아마 short-cut connection때문에 그러지 않을까 예상합니다. 하지만 둘 다 여전히 이전 픽셀들 전체를 고려하는게 아니라는게 단점입니다. 이걸 해결하기 위헤 PixelSNAIL는 attention block을 residual block과 함께 사용해서 long-dependency 관계도 고려하게 됩니다.
Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, and Pieter
Abbeel. Pixelsnail: An improved autoregressive generative
model. In ICML, volume 80 of Proceedings of Machine
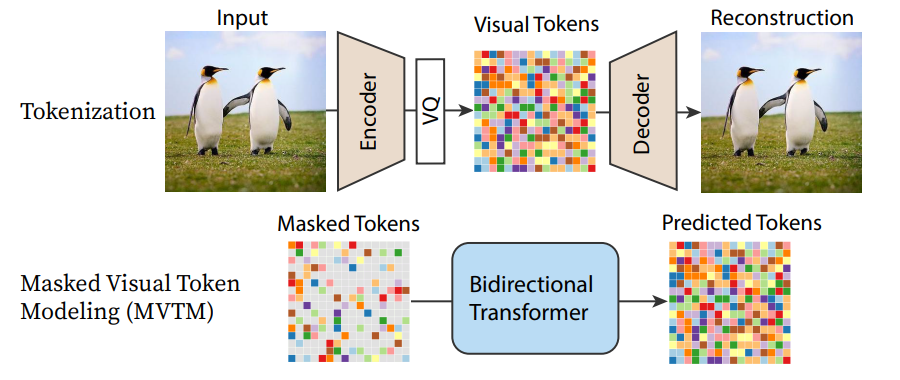
Learning Research, pages 863–871. PMLR, 2018) PixeCNN++의 문제 설정과 문제 해결법은 간단합니다. PixelCNN 구조로 더 뛰어난 성능을 보여줄 수 있다고 가설을 세웠고, 개선점들을 적용한 후 실제로 성능이 증가했다는 것을 보여줬습니다. 현재 PixelCNN/PixelCNN의 대표적 application은 latent 분포를 학습하는 데에 있습니다. 예를 들어 VQVAE의 latent 분포는 지정된 prior 분포가 아니고, 그 분포를 PixelCNN로 학습하게 되면 Encoder 없이 랜덤 생성이 가능합니다. VQVAE에서 Latent 분포를 PixeCNN으로 학습한다고 적어놨지만 현재 유행하는 방법은 mask prediction으로 분포 instance를 생성하게 됩니다. 그 뜻은 일분의 feature vector을 masking해주고 그 masking된 부분들을 예측하는 것이 학습 방식이 됩니다. 그러면 생성을 할때는 인풋으로 모두 마스킹 된 feature vector을 입력해주면 아웃풋으로 예측된 feature vector을 출력합니다.
여기서 장점은 모든 x,y coordinate에 모든 feature vector을 한 번의 feed forward으로 예측이 가능하다는 것이죠. 당연히 모든 인풋을 masking 해주면 생성 probability에 condition으로 활용되는 feature vector이 없기 때문에 생성 완성도가 낮을 수 있습니다. 따라서 생성된 feature vector을 일부 유지하고 나머지는 다시 masking 해주며 다시 인풋으로 입력해줍니다. 이런 작업을 t번 반복하면서 더 완성된 feature vectors (tensor)들을 생성하게 됩니다. 여기서 t는 feature vector 수보다 훨씬 적어서, autoregressive하게 feature vector마다 하나씩 생성하는 것 보다 t번에 모든 feature vector을 생성하는 것이 효율적입니다. 이런 feature vector이 이미지가 아닌 비디오 feature vector이면 효율적인 sampling의 중요성이 더욱더 부각됩니다.
Chang, H., Zhang, H., Jiang, L., Liu, C., & Freeman, W. T. (2022). MaskGIT: Masked Generative Image Transformer. arXiv. https://doi.org/10.48550/arXiv.2202.04200 



From PixelCNN to PixelSNAIL

Conclusion
Further Directions

Subscribe via RSS